How Meta Glasses Autocapture Will Train the Robotic Future (The Passive Lens)
We assume smart glasses are simply a convenient tool for recording our daily vacations and family moments. In reality the new autocapture feature is quietly crowdsourcing the exact first person training data required to animate the next generation of humanoid robots.

The transition from manual photography to passive algorithmic capture completely removes human friction from memory creation. This creates an absolutely unprecedented pipeline of flawless spatial data flowing directly into massive corporate servers.
Inspiration: Analyzing the rollout of the autocapture feature on Meta smart glasses and its massive implications for spatial computing. Realizing that passive human recording is the ultimate Trojan horse for collecting the foundational data required for embodied artificial intelligence.

The Friction of Memory
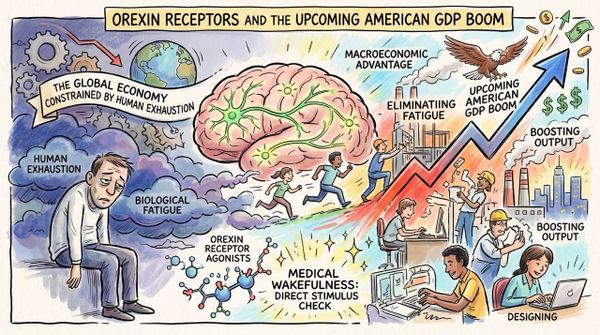
We currently experience a massive cognitive disruption every time we want to record a meaningful life event.
Reaching for a smartphone instantly rips us out of the present moment and forces us to view reality through a tiny digital screen.
The autocapture feature completely eliminates this biological friction by allowing an algorithm to silently record moments it deems culturally or personally significant.
The Algorithmic Photographer
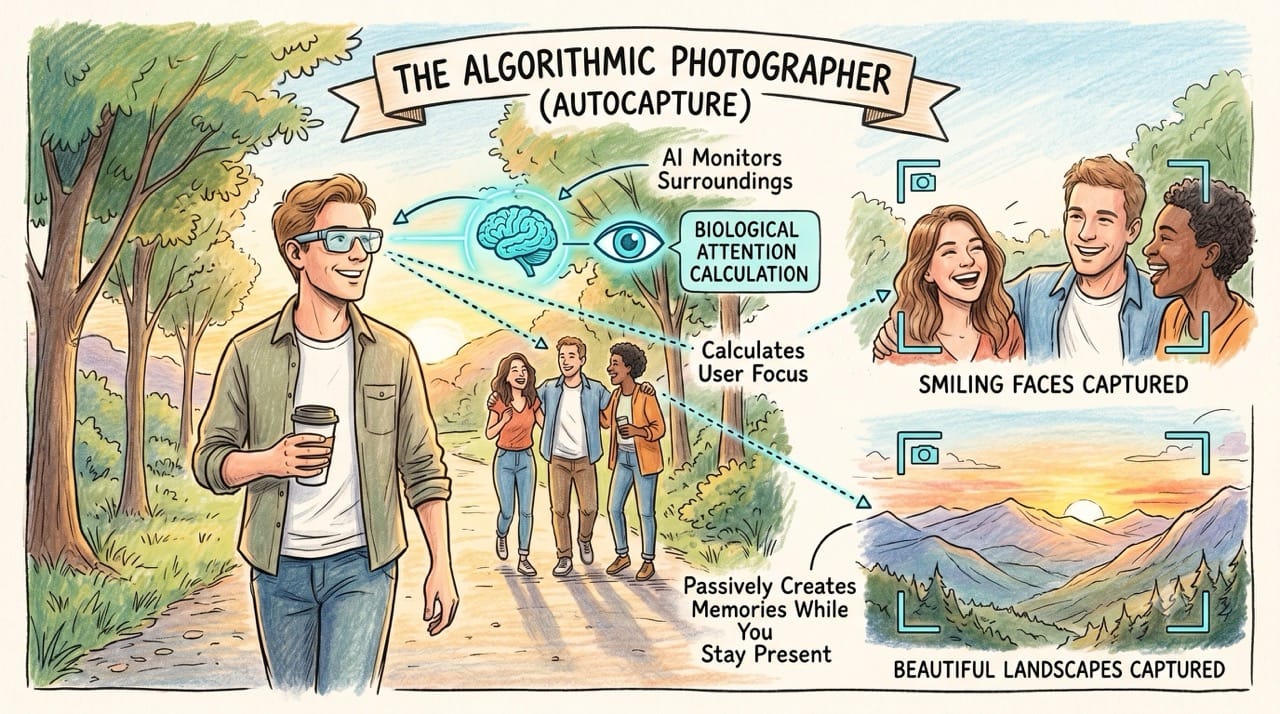
This specific feature transforms the physical glasses from a manual camera into a highly proactive algorithmic photographer.
The artificial intelligence actively monitors your surroundings and analyzes your physical behavior to mathematically calculate exactly what captures your biological attention.
It automatically snaps pictures of smiling faces or beautiful landscapes ensuring you never miss a memory while remaining entirely present in the physical world.
The True Commodity
While the immediate consumer benefit is absolute frictionless convenience the actual macroeconomic prize is the underlying data collection.
Millions of users are about to inadvertently provide Meta with an infinite stream of perfectly framed first person spatial awareness data.
The algorithm is essentially learning exactly how humans naturally navigate and prioritize completely chaotic physical environments.
The Robotic Bottleneck
As we previously analyzed regarding massive hardware rollouts spatial intelligence remains the absolute biggest bottleneck in modern robotic engineering.
You cannot easily teach a massive humanoid robot how to successfully navigate a cluttered kitchen using only text documents and synthetic software simulations.
True physical autonomy requires absolute mountains of authentic visual data recorded directly from the biological eye level of a human being.
Crowdsourcing the Future
The autocapture feature brilliantly solves this exact engineering deficit by crowdsourcing the training data directly from everyday consumers.
Every single passive photograph taken by a civilian wearing these glasses essentially teaches a future robot how to look at the world.
The algorithm learns to identify household objects recognize social cues and anticipate human movement entirely for free.
The Hardware Evolution
This massive influx of flawless spatial data will also dramatically accelerate the evolution of the physical hardware itself.
The artificial intelligence will instantly recognize structural inefficiencies and rapidly suggest architectural improvements for the next generation of augmented reality lenses.
We are building a perfectly closed loop where the software actively designs its own future physical container based entirely on raw environmental feedback.

Conclusion: The Ultimate Training Ground
We must stop viewing wearable technology strictly as a novel accessory for personal entertainment or social media broadcasting.
These passive lenses are highly sophisticated sensory ingestion modules quietly recording the fundamental physics of the human experience.
The corporation that successfully maps the human point of view will completely monopolize the incoming era of autonomous physical machinery.